I think there’s a new skill engineers need to learn: how to manage the context window well.
You always want as relevant and efficient use of the context window as possible. That’s the sweet spot where the next token prediction is way more likely to be what you actually expect.
The question is: How do you distill a large chunk of information down to only the parts that matter for the problem you’re trying to solve?
A Real Example
Let me walk through what I mean. I recently needed to write a detailed skill for setting up error monitoring with the Sentry SDK for Go. To do that properly, I needed to look at docs, verify which SDK version was installed, do web searches, maybe even try things out — a lot of ground to cover. That means a large context window just for the investigation phase.
Here’s the thing though: when I’m building something, I don’t actually care about all that investigation noise. I care about the result. The distilled, verified knowledge.
To solve this without trashing my main context window, I used my agent harness, Pi. I built a custom claude tool inside it that spawns a separate Claude Code agent to just do its thing — web search, file ops, running commands — and write its verified findings to a file.
So you can say something like: “Hey, install the Go SDK, try it out, see if it actually works, create a small example app” — you can go as detailed as you want. And the thing you’re actually interested in is: did it work? Did you verify it works? What’s the result?
Without paying the token cost for it in your main session.
Distilling Knowledge
So what Pi enabled me to do here is condense the knowledge of multiple context windows worth of usage — a lot — into one specific, up-to-date skill.
That means I could spend more time refining the distilled version to be exactly what I wanted, rather than being distracted by tiny side effects and constantly re-verifying things actually work.
I think this results in way higher quality output.
And this is as true for writing skills as it is for writing code.
The Workflow That Clicked
One thing that made this powerful is persistence. The claude tool doesn’t just stream output; it can write its final distilled findings to a markdown file. That knowledge is saved and accessible, not just floating in an ephemeral context window.
But the bigger “aha” moment—and maybe Pi’s most useful feature—is session forking. At literally any point in a conversation, you can slice the context window, fork off into a deep rabbit hole, and take a different path.
While building this tool, I forked the initial conversation about eight times. Each fork made the claude tool better. It was actually through this iteration that I realized having the agent write to a file was necessary. That loop of building, using, and improving the tool—all within the same session tree—is what made the whole thing click.
Sub-Agents Are the Same Idea
I recently tweeted that I can’t work without sub-agents anymore, and this is exactly why. You offload a messy task, and you only get back the verified, end-to-end result. They don’t just pretend it’s done; they build, test, and commit, delivering only the signal back to the main session.
What’s even cooler: because I gave my agent the claude tool as a capability, it started using it on its own. After a reviewer sub-agent came back with critical findings about the skill I’d written, the agent triaged them, created todos — and then just went ahead and fired off the claude tool to verify the questionable parts against the actual docs and source code. No prompting from me. It knew it had the tool and decided this was the moment to use it.
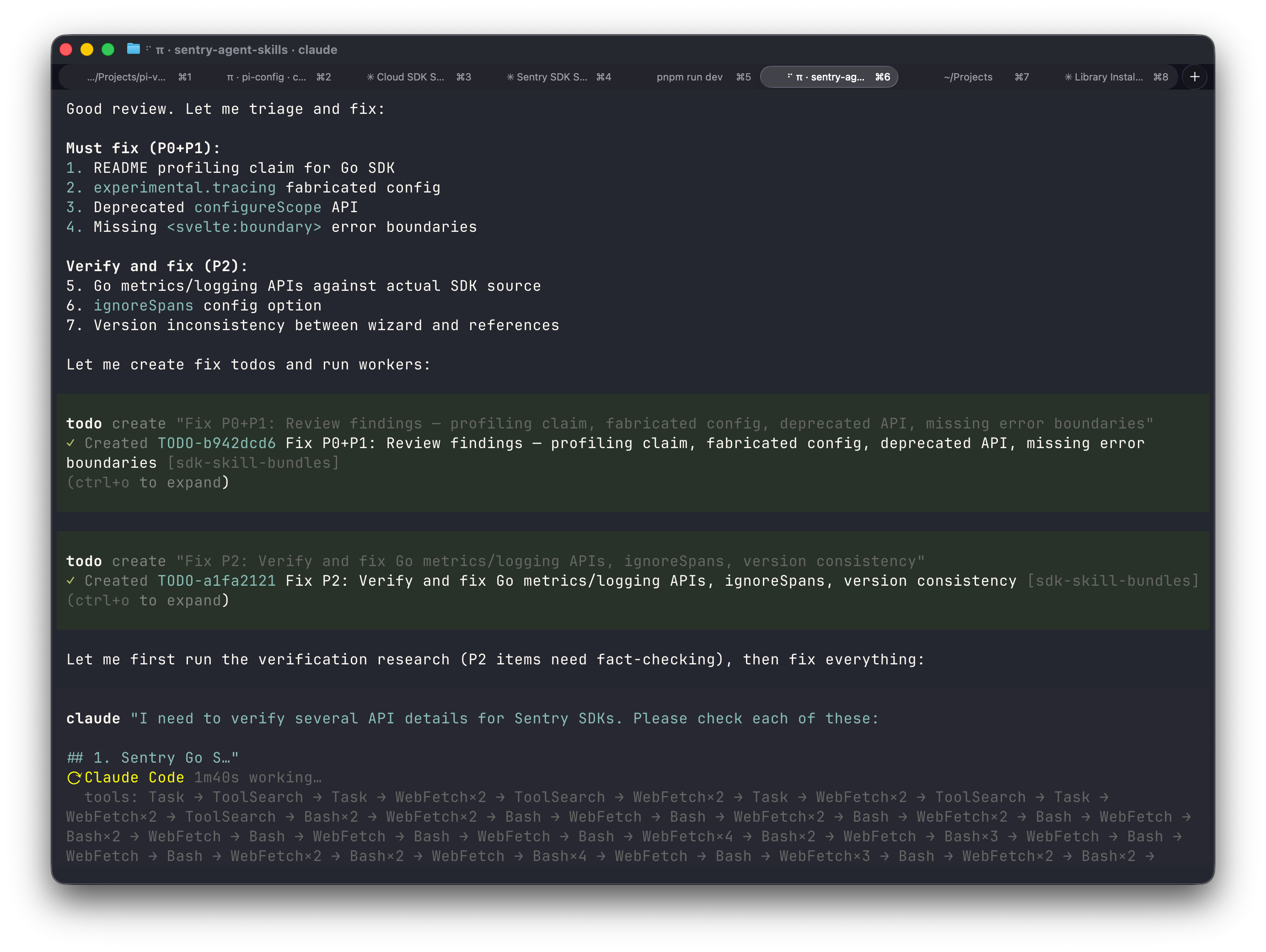
The end result? 7 commits, 4,158 lines of code across 15 files — using about half of the 200k context window. Roughly 34K tokens written. All verified, reviewed, and committed. From a process I mostly just steered.
It’s the same pattern everywhere: offload the noise, keep what matters.
Here is the PR of the thing I’m talking about, by the way.
Precision vs. Vibes
Pi is also my go-to tool when I’m actually engineering an application — not just vibing something together. When I precisely want to change specific parts and improve them, not just describe what I want and hope it works.
There’s a meaningful difference between those two modes.
In the end, I’m still learning this technique. Every day I find new ways to use Pi, and I keep catching myself thinking: “Wait, I can just give my agent the capability to do exactly this.”
I doubt that the claude tool I wrote for Pi is super helpful for many others. But for my use case, it solved the problem exactly the way I wanted to. And I will definitely keep using it.
Am I Overthinking This?
Maybe. I’m probably over-engineering this whole solution to a large degree.
And I think it’s safe to assume that maybe all of these things play themselves out over time and just become a normal part of how agents work. I don’t know.
But at least right now, at least a little bit, it feels like I’m getting more efficient at using the tool.
And honestly? That’s enough for now.